IDP- Intelligent document processing
🚀 Welcome to TechLearn India, your go-to destination for insightful tech tutorials, coding tips, and all things related to web development! 🌐💻
Who We Are: TechLearn India is a passionate community dedicated to fostering knowledge and skill development in the ever-evolving world of technology. Our mission is to empower learners, beginners to seasoned developers, with the latest tools, frameworks, and best practices in the field of web development.
What We Offer: 📚 Tutorials & Guides: Dive deep into our step-by-step tutorials, designed to make complex concepts accessible and enjoyable.
💡 Coding Tips & Tricks: Stay ahead of the curve with our curated collection of coding tips and tricks, helping you optimize your workflow and write cleaner, more efficient code.
🌐 Tech Insights: Explore the latest trends, insights, and news in the tech industry. We keep you informed about the cutting-edge technologies that shape the digital landscape.
Why TechLearn India: At TechLearn India, we believe in the transformative power of learning. Whether you're a beginner or a seasoned developer, our content is tailored to inspire, educate, and elevate your skills. We're committed to creating a supportive and inclusive learning environment for all tech enthusiasts.
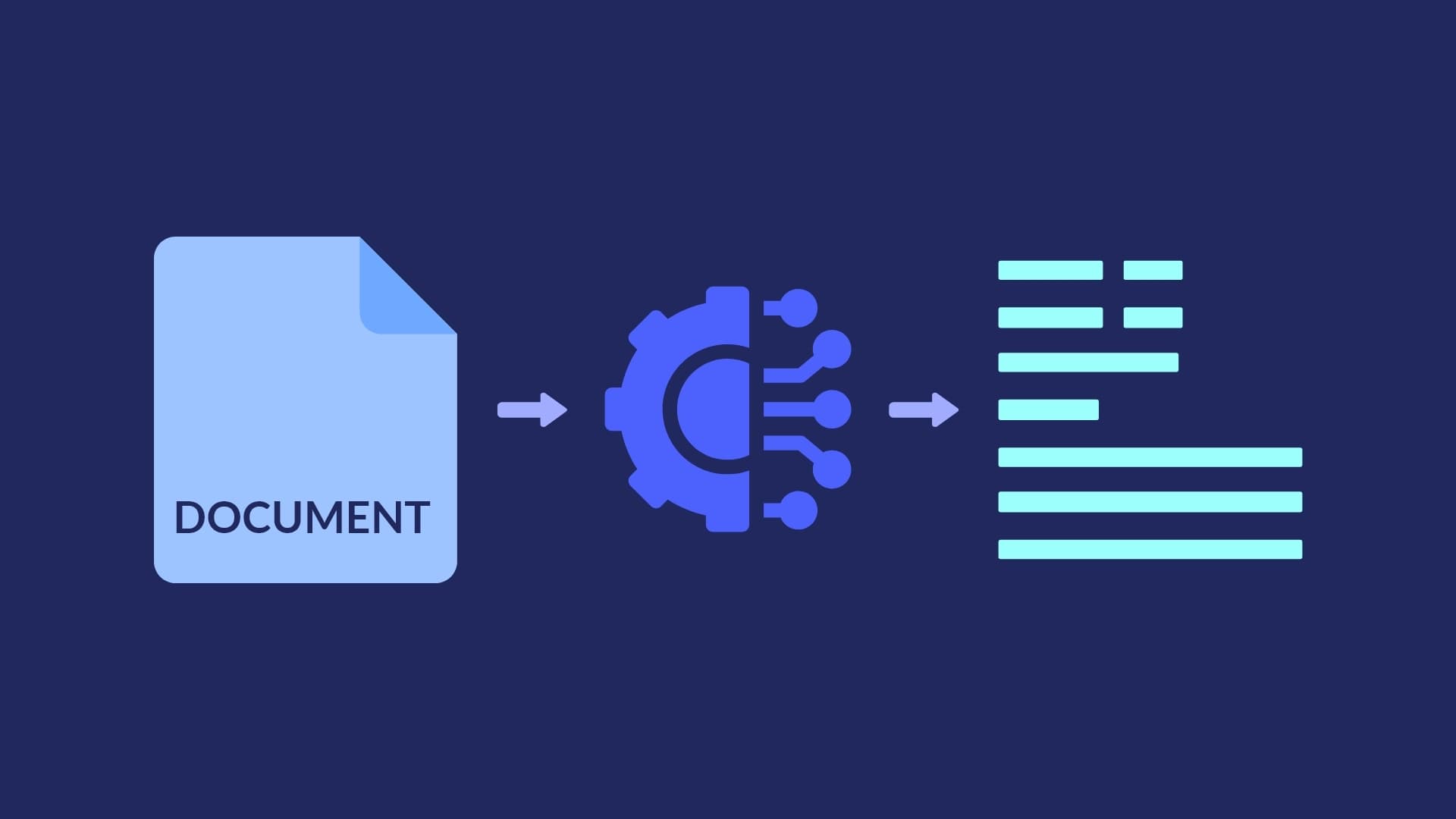
Intelligent Document Processing (IDP) transforms unstructured and semi-structured data/information into usable data.
In the Business Organization, 80% of all business data is embedded in unstructured formats like business documents, emails, images and PDF documents. And traditional document processing comes with some challenges that should be considered before a digital transformation project begins to avoid delays
Only uses one format for processing: Document processing uses pre-defined extraction rules to transform the relevant information into digital form. This type of data capture works great for structured data where the information is consistent. However, if you have large volumes of unstructured data or complex documents where the information provided is not consistent, the process can result in time-consuming errors.
Relies on processing experts: When issues and errors arise, they are often flagged for manual review by processing experts. This can be time-consuming and require significant human resources.
Difficult to continuously improve: Document processing systems lack operational visibility into how your document processing is functioning and what errors are commonly slowing the process down.
Intelligent document processing is the next-generation solution of automation, able to capture, extract, and process data from various document formats. It uses AI technologies such as natural language processing (NLP), Computer Vision, deep learning and machine learning (ML) to classify, categorize, extract relevant information, and validate the extracted data.
So, what exactly is intelligent document processing, and what are its different use-cases in different industries - we’ll find out in this blog.
What is IDP(Intelligent Document Processing)?
Intelligent Document Processing is the automation of data extraction from complex semi-structured/unstructured documents and converting them into structured usable data. It is also referred to as Cognitive Data Processing or Intelligent Data Capture.
Data extraction from a document is done in three ways it can be manual, template based or Intelligent Document Processing. Manual entry of Data involves lots of human work, it is time consuming and can’t give 100% accuracy as a human is to err so sometimes it contains missing values, wrong values or information. Template-based data extraction uses rule-based software and gives 85%-90% accuracy while Intelligent Document Processing uses OCR software to extract the data and further process it with NLP(natural language processing) for document processing and it gives accuracy of more than 98%.
IDP is often used interchangeably with OCR which is wrong because IDP is the next-generation data extraction technology developed only to overcome the limitations of traditional OCR in extracting data from more complex and non-standard documents.
To make it simpler, OCR is a subset of IDP but the reverse is not true. That means, IDP uses traditional OCR to extract data at some level but IDP goes beyond it. With the help of Named-entity recognition and classification, supervised/unsupervised learning, and NLP context analysis, IDP has a lot more to offer for improved accuracy in document processing and analysis.
If you need to know more about OCR you can read another blog on OCR.
How does Intelligent document Processing works?
IDP has the following steps -
Document preparation: In this step, physical documents are sorted, organized, and prepared for scanning. This may involve removing staples, flattening creases, and arranging the documents in the correct order.
Scanning: The documents are scanned using a high-quality scanner that captures images of each page. The scanned images are usually saved in a standard file format like PDF or TIFF.
Image preprocessing: The scanned images are processed to improve the quality and readability of the text. This may involve adjusting the brightness, contrast, and sharpness of the images, removing noise or artifacts and deskewing or despeckling the images.
Optical character recognition (OCR): The scanned images are processed using OCR software that converts the images into machine-readable text. The OCR software analyzes the images and attempts to recognize the characters and words in the text.
Data extraction: The machine-readable text is processed using natural language processing (NLP) techniques to extract the relevant information from the document. This may involve identifying key phrases or entities, classifying the document type, or extracting specific data fields like names, dates, or addresses.
Verification and validation: The extracted data is reviewed and validated to ensure accuracy and completeness. This may involve manual review by human operators or automated checks to compare the extracted data against existing databases or reference data.
Output and storage: The final output is generated in a machine-readable format and stored in a database or other digital storage system for further processing or analysis
Intelligent Document Processing (IDP) provides:
Direct cost savings. Reduces expenses by dramatically cutting costs to process large volumes of data
Higher straight-through processing (STP). Minimize the need for knowledge workers to manually process documents
Ease of use. Allows businesses to get set up faster and automate more processes
Process efficiency. Enables end-to-end automation of document-centric processes
Accuracy uplift. See immediate significant increases in data accuracy with the use of AI
Strategic goal boost. Automated data processing supports business goals like improving customer experience
Use cases for document processing
These are a few of the most common situations in which you could use document processing:
Invoice/payroll: Digital transformations require manual invoicing and payroll systems to be digitized and automated.
Insurance: Document processing allows you to extract data from forms and quickly verify coverage and eligibility. It also keeps documents consistent with industry standards and protocols and protects sensitive documentation and personal information.
Human resources: Use document processing to convert employee and candidate data into valuable insights that optimize staff management and hiring decisions.
Fraud detection: Document processing has become a valuable tool to financial services, authorizing signatures on checks and determining the authenticity of high-volume transactions to eliminate banking discrepancies.
Mortgage: Mortgage processing requires that lenders process millions of paper documents each year. Document processing ensures quick and simple document retrieval and increases the speed and scale of mortgage filing.
Readers today we learned about IDP, what it is and how it works.See you in the next blog.
HAPPY LEARNING.




